


In Production environment, we often face scenario, where we need to list down all the files available inside root folder recursively. If the root folder has huge list of folders and subfolders, then it will be a time consuming process to list down all the files.
In this post, we will check on how to list all the files either in azure blob storage or hadoop or in DBFS. We will discuss on the available approaches. its advantage and limitation.
Method 1 - Using dbutils fs ls
With Databricks, we have a inbuilt feature dbutils.fs.ls which comes handy to list down all the folders and files inside the Azure DataLake or DBFS.

With dbutils, we cannot recursively get the files list. So, we need to write a python function using yield to get the list of files.
Below is the code snippet on py function,
def get_file_list(ls_path):
for dir_path in dbutils.fs.ls(ls_path):
if dir_path.isFile():
yield dir_path.path
elif dir_path.isDir() and ls_path != dir_path.path:
yield from get_file_list(dir_path.path)
lis=list(get_file_list("dbfs:/FileStore/"))
df_list=spark.createDataFrame([[i] for i in lis],["path"])
df_list.display()
Out[]:
Limitation on dbutils.fs.ls
It consumes more time to extract the list of files into Spark Dataframe, if you have many subfolder inside the root directory ie., Time taken to extract is directly proportional to the number of folder available to list files.
We can use wildcard search inside the fs utility, and it throws error as FileNotFound as shown in below figure.
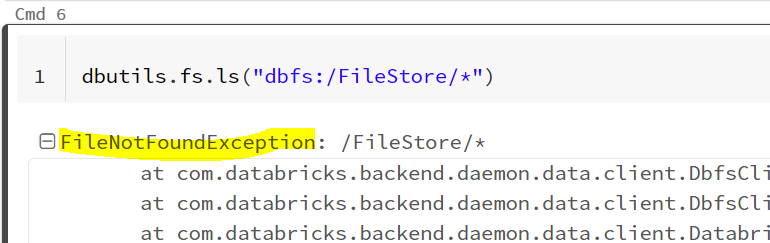
Advantage:
The major advantage of using the dbutils.fs.ls is,
- It works faster with the delta file formats
- Even all the hidden files are also listed.
Method 2 - Using SparkHadoopUtils
In this method, we will check on Spark Hadoop Utils available in Spark Scala to list all the files from different source systems. It utilizes the globpath feature along with in memory indexing and bulk list leaf approach to extract and list all the files. We will go through the code snippet and have a detailed explanation.
Code Snippet:
In this method, we are able to extract the list of files recursively through all the folders faster than the above given dbutils.fs.ls method
Step 1: Import libraries
//import all the required packages
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{Path, FileSystem}
import org.apache.spark.deploy.SparkHadoopUtil
import org.apache.spark.sql.execution.datasources.InMemoryFileIndex
import java.net.URI
Step 2: Define the function//Function definition to list files
def listFiles(basep: String, globp: String): Seq[String] = {
val conf = new Configuration(spark.sparkContext.hadoopConfiguration)
val fs = FileSystem.get(new URI(basep), conf)
def validated(path: String): Path = {
if(path startsWith "dbfs") new Path(path)
else if(path startsWith "abfss") new Path(path)
else if(path startsWith "/") new Path(path)
else new Path("/" + path)
}
val fileCatalog = InMemoryFileIndex.bulkListLeafFiles(
paths = SparkHadoopUtil.get.globPath(fs, Path.mergePaths(validated(basep), validated(globp))),
hadoopConf = conf,
filter = null,
sparkSession = spark, areRootPaths=true)
fileCatalog.flatMap(_._2.map(_.path))
}
The listFiles function takes two arguments, first one as a base or root path and the second one will be a glob path. This Function scans the files and matches with the glob pattern, and then returns all the leaf files that were matched as a sequence of strings. It also uses the Spark Hadoop utility function on globPath from the SparkHadoopUtil library. This function lists all the paths in a directory with the specified prefix, and does not further list leaf children (files). The list of paths is passed into InMemoryFileIndex.bulkListLeafFiles method, which is a Spark internal API for distributed file listing.
Neither of these listing utility functions work well alone. By combining them you can get a list of top-level directories that you want to list using globPath function, which will run on the driver, and you can distribute the listing for all child leaves of the top-level directories into Spark workers using bulkListLeafFiles.
Step 3: List and Load in Spark DF
//Root or the base path - Can be /mnt or abfss:// or dbfs:/
val root = "dbfs:/"
//Parameterize the below line -
//can be provided with pattern and wildcard aswell
val globp="/FileStore"
val files = listFiles(root, globp)
val df_list_files=files.toDF("path")
display(df_list_files)
Out[]:
The speed-up can be around 20-50x faster according to Amdahl’s law. The reason is that, you can easily control the glob path according to the real file physical layout and control the parallelism through spark.sql.sources.parallelPartitionDiscovery.parallelism for InMemoryFileIndex.
Limitation:
Only limitation that I could observe in this method is, all the hidden files or folder starting with underscore (_) or dot (.) is not extracted using this method.
Try implementing in your spark application development and let me know your comments on the performance improvement.
Happy Learning !!!
Reference:
- https://stackoverflow.com/questions/63955823/list-the-files-of-a-directory-and-subdirectory-recursively-in-databricksdbfs
- https://docs.databricks.com/dev-tools/databricks-utils.html
- https://learn.microsoft.com/en-us/azure/databricks/kb/data/list-delete-files-faster




{kind=link}
5 Comments
Hi. Is there a nice way to get along with path, Size Of File, CREATION TIME, LAT MODIFICATION TIMe ?
ReplyDeleteI'm having a folder that contain 500 000 subfolders. Each subfolder can contain couple images (.jpg or .JPG ) or rarely video with .mpg extenstion. Apart of getting path ( i can use this code to get pathes ) i would like to get FileSize, Created Date and Modification date. Ho to modify this code to achive my desired results, as i'm completely new to SCALA :)
DeleteThank you for this post. The code lines about abfss saved my life.
ReplyDeleteI'd like to try out the method2 in my scala code;
ReplyDeletebut i found the sparkHadoopUtil is private to spark packge. spark_core_2.12-3.2.2
am i looking at the wrong place?
I tried with the following approach and it was pretty fast .
ReplyDeletefile_list = []
folder_list = ['dbfs:/FileStore/']
while (len(folder_list)>0):
for filedetail in dbutils.fs.ls(folder_list.pop(0)):
if filedetail.path.endswith('/'):
folder_list.append(filedetail.path)
else:
file_list.append(filedetail.path)